案例研究
六年走向 AI:一个实验室是如何把基础设施搭建成让 AI 真正有用的样子
从纸质笔记本到跨 19 个项目的自然语言查询
Oleksiy Penkov · 浙江大学终身教授· 2026年5月7日
两个场景
2019 年,韩国。 一位研究生敲门进来。最近一批 Mo/B 多层膜不对——周期偏了。他翻开笔记本,记录写着「Mo/B 300W 120s」。没有腔体压强,没有气体流量,没有衬底编号。沉积日志?据说在某台旧电脑上的某个文件夹里,他记不清是哪个了。两个小时后我们找到了日志:腔体压强超出标准 50%,几乎可以确定是法兰漏气,而没有人提起过。又花了一小时找到 X 射线数据——在一个 U 盘里,文件夹叫 new_new_final。结果:损失了一天,五块样品报废。
2026 年,中国。 我在终端里输入:「比较样品 260202A 和 260202B 的沉积日志。两个使用相同配方,但 B4C 靶用了不同的电源。请与 XRR 拟合结果交叉对比。」 三十秒后答案出来了:在相同的电流设定值下,电源 C 输出的功率比电源 B 高 6%,这解释了为什么 C 沉积的样品中 WC 界面层系统性地更厚。四种文件格式。八个数据文件。几分钟,而不是几天。
这是同一个问题——这次镀膜为什么不对——我已经追问了十五年,先在韩国,后来在中国。第二个场景里改变的不是 AI,而是这一次,回答这个问题所需要的数据真的就在那里、可以被读取。
没人写论文的那部分数据问题
任何做实验的物理实验室都会产生大量数据:衍射图、显微照片、沉积日志、力学测试结果、工艺参数。大多数实验室都把这些数据管得不算好——而每家糟糕的方式都不太一样。
有的人记纸质笔记本。条目极简——「Mo/B 300W 不错」。一周以后,没有人记得「不错」是什么意思。研究生答辩走人,把上下文也带走了。
有的人建立繁复的文件夹树:2022/March/Week2/Mo-B/attempt3_final_FINAL2/。两百 GB 整齐分类的文件,只有作者本人能找得到东西,而且只能找半年。
还有一种类型活在 Excel 里:一个主文件,四十七个工作表,公式引用「原始数据(旧)」表,那张表又引用另一台电脑上的外部文件。打开要三分钟。在别人电脑上根本打不开。
我自己在不同时期分别做过这三种类型的每一种。这些失败不是道德问题,而是结构性问题——研究生培养中没有任何一门课教你怎么把数据组织成下一届学生还能读得懂的形式。你想出一套办法,对自己来说够用,一年后你离开,没人再看得懂。
这些方式都没有解决核心问题:把过程和结果连起来。 你去年做了五十次 Mo/B 沉积。哪些沉积参数和最高反射率相关?要回答这个问题,必须手动把每个样品的沉积日志和衍射数据配对——然后发现三份日志丢了,两张衍射图没标注,还有一个样品在笔记本里和硬盘上的命名不一样。
那不是研究。那是考古。
不那么光鲜的那几年
数字化没有从宏大的计划开始。它始于 2020 年的一套磁控溅射沉积系统的控制软件,软件管转盘、电源、挡板、离子枪——因为不写软件就要在腔体旁边站五个小时一片样品。
沉积控制是显眼的成果。更有意思的副产物是一个 32 通道的 TSV 日志:腔体压强、电压、电流、功率、各路气体流量、挡板状态、转盘位置——每一秒记录一次每一项参数。一次镀膜的日志大约 1.5 MB 的纯文本。当时我们对这些日志没多想——只是个调试工具,仅此而已。六年之后,它们成了那套软件留下的最有价值的东西。
2021 年 1 月,电子实验记录本上线。它的层级反映了实验室真实的工作流程:
项目 → 文件夹 → 样品 → 操作 → 文件
每一块物理样品都是系统中的一个 Specimen,带名称、衬底类型,和一个用来记录关键结果的 Outcome 字段。每一项对它做的操作——沉积、退火、XRD、SEM、压痕、划痕测试——都是绑定到具体设备的 Action。原始数据文件挂在产生它们的 Action 上:衍射仪给的 .xrdml、X-Ray Calc(我们的开源 XRR 拟合软件)的 .xrcx、.dsc 配方文件、.mit 压痕结果。除了文件,每个 Action 还可以挂结构化的 Key-Values——多层膜周期、硬度、摩擦系数、粗糙度——也就是你真正需要在几百块样品上查询的那些数字。
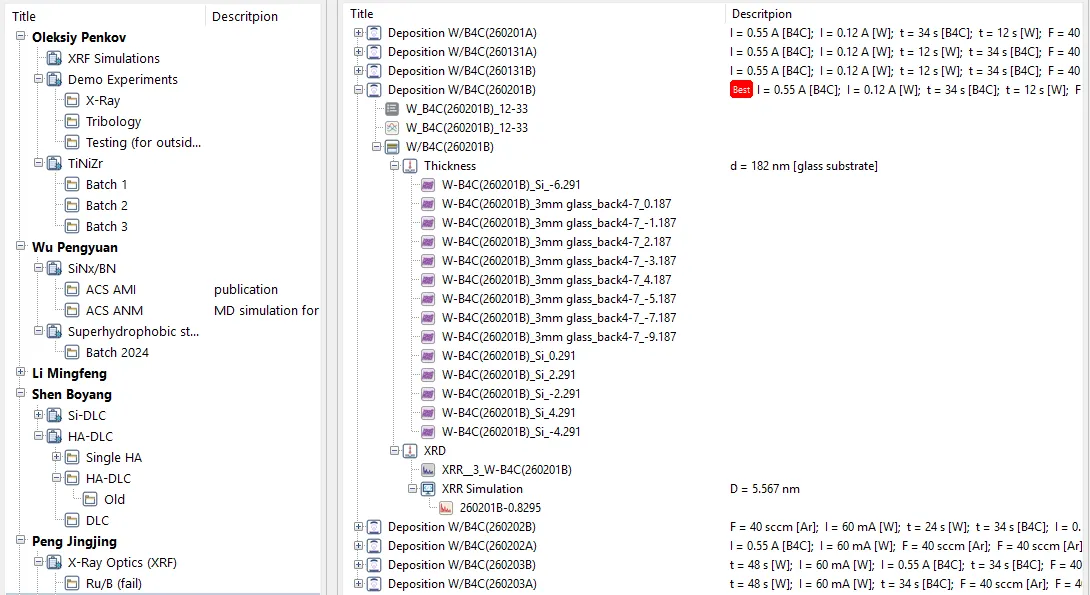
层级:项目 → 文件夹 → 样品 → 操作 → 文件。每一项测量结果都待在你预期能找到它的地方。
接下来是几年不那么光鲜的纪律。每一块样品都登记。每一张衍射图都上传并打标。每一份沉积日志都挂到正确的 Action 上。每一项 Key-Value 都填好。给每种仪器的私有格式写插件,让数字从厂家软件里解放出来、变得可查询。
枯燥吗?枯燥到极点。这种纪律有过半打次差点崩溃——通常发生在论文截稿之后,那时候「样品先放着,回头再录」的诱惑最大。真正撑住它的不是意志力,而是把录入做得比跳过录入更省事:键盘快捷键、合理的默认值、能从你刚拖进去的文件里自动填一半字段的插件。
这是数字化中没人发论文的那部分。到 2026 年:19 个项目,几百块样品,几千份文件。一段连续的五年实验室历史。
一次故障侦查
2026 年 3 月,我们做了一批 W/B4C 多层膜镜——30 个双层周期,用于 X 射线荧光光学。腔体里有两台脉冲直流电源,标号 B 和 C。我们在系列实验中轮换两台电源所驱动的靶,理论上选哪台都不应该有差别。配方相同。设定值相同。除了电源,其他都一样。
但 XRR 拟合结果不一样。
我最初的猜测是某个细微的东西在两次实验之间漂移了——但配方完全一致,意味着我已知的那些变量都已经控制住了。所以我让 Claude——通过我们写的一个 Model Context Protocol 服务器连到实验记录本——去找出我漏掉了什么。
Claude 调用 MCP 工具——get_experiment、extract_file_data、correlate_values——以与研究员相同的方式遍历数据库。
第一步: AI 取出两批样品的沉积配方文件(.dsc),逐字节比较。除了指明哪台电源驱动靶的那一行,其他完全一致。
第二步: AI 解析了 32 通道的沉积日志。两台电源的设定值都是 550 mA,但电源 C 实际输出 464–478 V,而电源 B 是 458–471 V。功率差大约 6%——除了日志,没有任何记录提到过。
第三步: AI 取出 XRR 拟合文件(.xrcx),读出每一层的厚度。用电源 C 沉积的样品在 48 秒钨沉积条件下 WC 界面层为 20.4 nm。用电源 B 的同样条件下:9.1 nm。
第四步: AI 把结论写出来——电源 C 输出功率更高意味着 W/B4C 界面处的离子能量更高,这驱动了更多界面混合。建议:在做后续对比实验之前,先对两台电源做交叉标定。
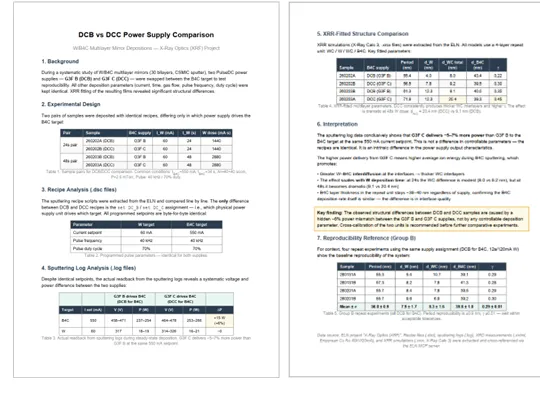
由一句自然语言提问端到端生成的最终报告。表格、结论、建议——可以直接放进组会讲。
四种文件格式。八个数据文件。四组实验加上四组对照。一名研究员可以做同样的调查——花一两天的细致工作。AI 用了几分钟。
但那只是因为数据已经在那里了。结构化的、绑定到样品的、能通过 API 访问的。如果日志「在某台旧电脑上」、衍射图「在 U 盘的 new_new_final 文件夹里」,再厉害的 AI 也帮不上忙。
真正花的代价
现在大家都很兴奋 AI 在科研里的应用。会议上的 AI 驱动材料发现报告。期刊上的薄膜机器学习优化论文。每份基金申请里都必须提到人工智能。
几乎所有这些工作都从同一个不言自明的假设开始:我们有一个干净的、结构化的数据集。 数据集从哪里来——这一点鲜有人提。
事实是,绝大多数实验室根本没有用 AI 处理自己数据所需要的数字基础。它们的数据存在笔记本里、Excel 文件里、个人 U 盘里、刚毕业的研究生的脑子里。语言模型读不了手写体,也无法找回从来没有被记录下来的东西。
我们的集成时间线本身就把事情说得够清楚了。把 Claude 接入实验记录本花了一天。写 MCP 服务器花了两周。搭建底下那层基础设施花了六年——而这一段是没办法压缩的。
沉积控制软件。实验记录本。各种数据提取插件。以及——比上述任何一项都更重要——把每一块样品、每一项测量、每一项参数都登记下来的日常习惯。没有这种习惯,AI 只是一个能信心十足地讨论薄膜物理却完全不知道你的电源已经漂了三周的聊天机器人。
第一次往往最难。Mo(210121-A)——10×10 mm 硅衬底上的钼,2021 年 1 月——是我们录入系统的第一个样品。这条记录本身没有什么内在价值。有价值的是:之后的每一条都遵循同样的规则。