案例研究
AI 眼中的实验研究组
围绕结构化电子实验记录本搭建的 PI 工具层,以及它所支撑的查询
Oleksiy Penkov · 浙江大学终身教授· 2026年5月8日
协调问题
实验研究组的负责人(principal investigator,下文简称 PI,亦称导师)通常会同时指导四到十二名研究生与博士后。每位成员都在各自的课题上工作,使用一台或多台共用仪器,提交每周进展报告,积累原始测量数据,并间或参与论文产出。PI 是跨越多年研究主线的唯一连续线索,也是把分布式实验工作整合在一起的唯一节点。
关于科研中人工智能的讨论压倒性地集中在数据与分析层面:用于材料发现的机器学习模型、从仪器文件中自动提取的工具、替代昂贵模拟的代理模型。PI 每天面对的问题不是分析,而是 协调——知道目前正在发生什么、由谁在做、用哪台仪器、对应哪一个假设。大语言模型的最近进展,加上对课题组记录的结构化访问能力,使 AI 现在能够成为对协调问题本身的回答,而不仅仅是对分析问题的回答。
PI 需要追踪的东西
一个运转中的实验研究组的管理面相当宽。本案例所描述的课题组提供一个具有代表性的清单:每位成员提交的每周进展汇报;横跨两间溅射实验室的设备使用与时间冲突;三种薄膜材料体系的沉积配方;正在推进的成果(在审论文、会议报告、资格考试草稿);针对已记录产出进行答辩的年度绩效评估;以及面向基金申请的预备数据汇编周期。
通用工具在这个规模上失效的原因是可预测的。共享磁盘的搜索不超过文件名。聊天记录的可持久性不超过最近一个月。电子表格无法跨课题、跨学生、跨仪器组合。最终结果是一笔随课题组规模增长的协调税,而几乎完全由 PI 在晚上和周末支付。
一个 AI 可以读的工作目录
本案例所描述的课题组维护着一个同步文件夹 MultilayerLab/,作为面向 PI 工作的运营中心。它与电子实验记录本相区分——电子实验记录本承载的是实验、样品和测量的规范性记录。这个工作目录坐落在电子实验记录本之上,存放电子实验记录本本身并不适合容纳的内容:
lab-reports/—— 自 2022 年以来积累的约 2,700 份每周汇报演示文档的索引,通过 Model Context Protocol(MCP)服务器暴露给大语言模型。recipes/—— 三种材料体系(W/B₄C、W/Si、Ru/C-B-Si)的沉积配方,作为操作员所依据的唯一版本。performance-reviews/—— 基于电子实验记录本中结构化证据撰写的年度绩效评估。deliverables/—— 论文、报告、资格考试草稿。mirrored-eln/—— 电子实验记录本数据的只读镜像,用于离线参考。
这个文件夹是纯文本的、有版本控制的、结构化的。它是连接到该课题组的 AI 助手每天早上读取的对象。它作为一个独立工件存在——独立于电子实验记录本、独立于任何单一课题——是一个有意的设计选择:PI 的视角与任何一项实验的视角并不相同。
AI 替 PI 回答的问题
下面是过去一个季度内具有代表性的三个查询,每一个都以自然语言提给通过 MCP 服务器连接到课题组记录的大语言模型。
「本季度有哪些每周汇报幻灯片提到了 Mo/Si 腔体?」 LabReports MCP 服务器返回匹配的幻灯片、所在的演示文档、作者以及日期。这件事过去先是一条 Slack 线索,再是一次文件夹遍历;现在是一句话。
「某位研究生在二月到四月之间的标志性结果是什么?」 一次跨越每周汇报存档与结构化实验记录的组合查询。模型返回幻灯片中引用的结果,沿着引用回到电子实验记录本中对应的样品,并标出下次组会上该学生最可能被问到的两次测量记录。
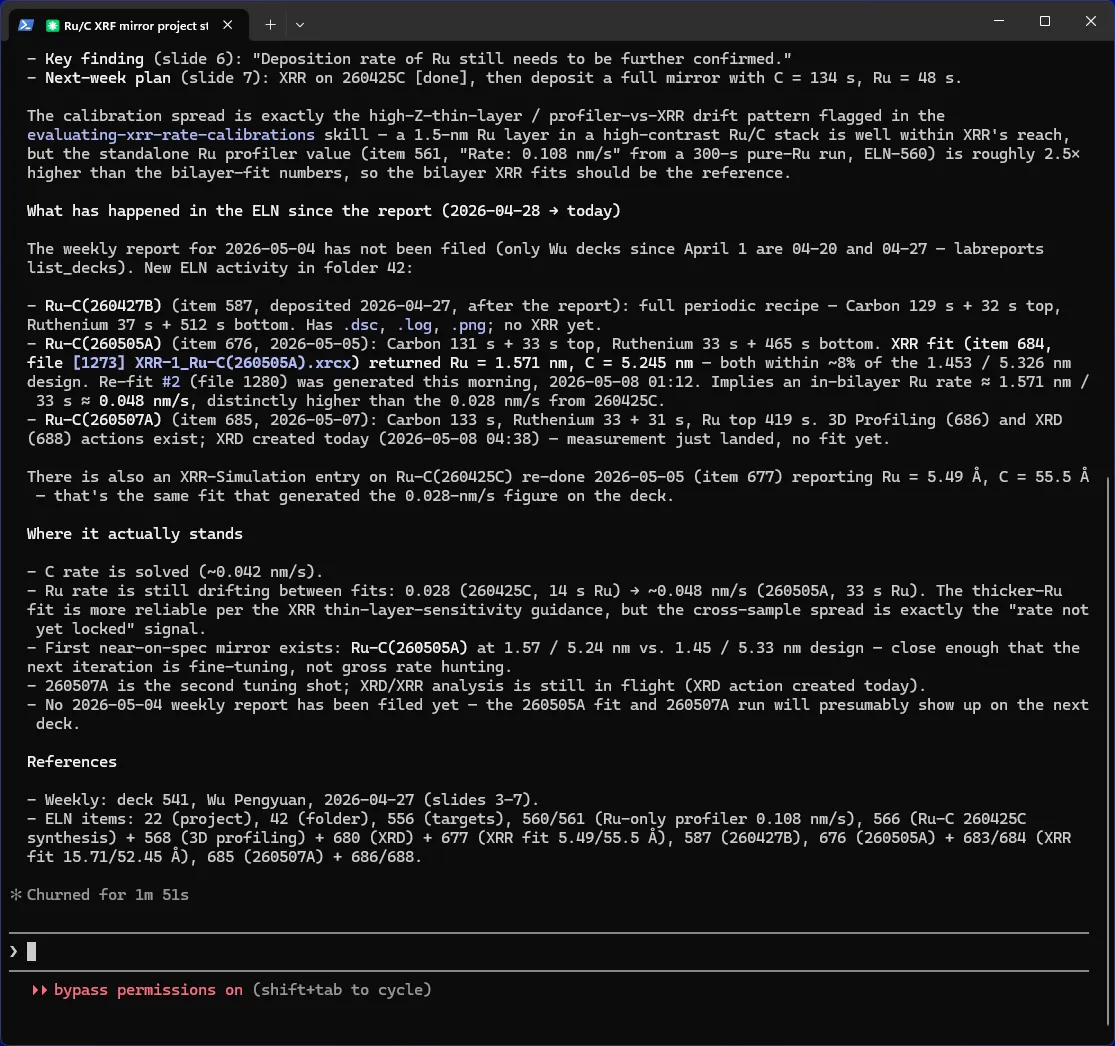
「Ru/C XRF 反射镜项目当前进展如何?」 模型走查最近一份每周汇报演示文档,识别会上提出的 Ru 沉积速率校准问题,然后在电子实验记录本中依次走查该汇报之后的每一条 Ru/C 记录——三块新样品、今晨返回的一份 XRR 拟合、今天刚刚到位的一项 XRD 测量——并返回一份状况报告,明确给出速率分布(约 0.028 至约 0.048 nm/s)以及下一步的决策点。
三者的共同结构一致。一个自然语言问题。一组走查结构化记录的 MCP 工具调用。一份带有引用、可追溯到具体样品、演示文档与仪器的回答。PI 不需要学习查询语言。AI 走查记录的方式与一名资深学生相同,只是用秒计。
两层底座
AI 之所以能够工作,是因为记录已经在那里、可以被读取。电子实验记录本承载着一套层级——课题、文件夹、样品、操作、文件——使关于一台腔体或一位成员的提问能够解析到具体的样品和测量上,而不是解析到聊天记录上。每次实验都登记、每次测量都附上、每个参数都填入的纪律性,是查询能够返回引用而非猜测的前提。本站的另一篇案例描述了产生这层底座所需的、长达六年的不那么光鲜的基础设施工作,以及当 AI 终于能读懂它的那个月发生了什么改变。参见六年走向 AI:一个实验室是如何把基础设施搭建成让 AI 真正有用的样子。
同一个 AI 还能伸回到多年前已经结束的课题里。当一个研究组对已结束课题以与在线课题相同的纪律性进行入库时,研究组的机构记忆便变得可查询。一份关于准晶薄膜的、跨越两篇期刊论文与四个时区的三位研究生、长达六年的旧档案,在 2026 年 3 月被注入电子实验记录本——平均每篇论文约十小时的工作量,由此产生了此前只存在于原作者记忆中的跨论文样品谱系。参见旧数据有第二段生命。
给考虑这一做法的 PI
来自上述课题组的三点观察,提供给正在考虑类似工具层的 PI。
第一,结构化的电子实验记录本是一项跨年的承诺,而不是一个季度的项目。底座必须先就位,关于 AI 的路线图讨论才有意义——语言模型无法挽回从未被记录下来的东西。
第二,运营层工具——每周汇报索引、配方登记、绩效评估流水线——应当随着同一种查询重复到值得自动化的程度,逐步累积。过早的系统化只会留下一堆没人用的脚本目录。
第三,把运营层当作放在版本控制中的代码,而不是放在共享磁盘里的文档。语言模型在面向代码仓库时的工作效果优于面向格式各异的文件夹。有意思的工作——AI 在上层做的分析——前提是它下面的那一层已经存在。