Case Study
What an AI sees of an experimental research group
PI-facing tooling around a structured lab notebook, and the queries it makes possible
Oleksiy Penkov · Tenured Faculty, Zhejiang University· May 8, 2026
The coordination problem
A principal investigator (PI; also: supervisor or group leader) in an experimental research group typically supervises between four and twelve graduate students and postdoctoral fellows concurrently. Each operates on a distinct project across one or more shared instruments, generates weekly progress reports, accumulates raw measurement data, and contributes intermittently to publications. The PI is the only persistent thread across multi-year research arcs and the sole point of integration for distributed experimental work.
The literature on artificial intelligence in science focuses overwhelmingly on data and analysis: machine-learning models for materials discovery, automated extraction from instrument files, surrogate models for expensive simulations. The PI’s daily problem is not analysis. It is coordination — knowing what is happening, by whom, on which instrument, against which hypothesis. Recent advances in large language models, paired with structured access to a group’s records, make AI a plausible response to the coordination problem itself, not only to the analysis problem.
What a PI must track
The oversight surface in a working experimental group is broad. A representative list, drawn from the group described in this case study: weekly progress reports submitted by each researcher; equipment usage and calendar conflicts across two sputter laboratories; deposition prescriptions for three thin-film material systems; deliverables in flight (papers under revision, conference talks, qualifying-exam drafts); annual performance reviews defended against documented output; and the preliminary-data assembly cycle for grant proposals.
Generic tools fail at this scale for predictable reasons. Shared drives are not searchable beyond filename. Chat threads are not durable beyond the most recent month. Spreadsheets do not compose across projects, students, or instruments. The result is a coordination tax that scales with group size and is paid almost entirely by the PI, in evenings and weekends.
A workspace the AI can read
The group described here maintains a synced folder, MultilayerLab/, that serves as the operational hub for principal-investigator-facing work. It is distinct from the electronic lab notebook, which holds the canonical record of experiments, specimens, and measurements. The workspace sits on top of the notebook and contains the artifacts the notebook is not designed to hold:
lab-reports/— an index over approximately 2,700 weekly-report decks accumulated since 2022, exposed to a large language model through a Model Context Protocol (MCP) server.recipes/— deposition prescriptions for three material systems (W/B₄C, W/Si, Ru/C-B-Si) maintained as the single source of truth for the operators.performance-reviews/— annual reviews drafted against structured evidence drawn from the notebook.deliverables/— papers, talks, qualifying-exam drafts.mirrored-eln/— read-only mirrors of notebook data for offline reference.
The folder is plain text, version-controlled, and structured. It is what an AI assistant connected to the group reads each morning. Its existence as a distinct artifact — separate from the notebook, separate from any one project — is a deliberate choice: the PI’s view is not the same as any single experiment’s view.
Questions the AI answers for the PI
Three representative queries from the past quarter, each posed in natural language to a large language model connected to the group’s records through MCP servers.
“Which weekly-report slides this quarter discuss the Mo/Si chamber?” The LabReports MCP server returns the matching slides, the decks that contain them, the authors, and the dates. Previously a Slack thread, then a folder traversal; now a sentence.
“What were a named researcher’s headline results between February and April?” A combined query across the weekly-report archive and the structured experimental record. The model returns the cited results from the decks, walks back to the underlying specimens in the notebook, and surfaces the two measurement runs the student would be asked about in the next group meeting.
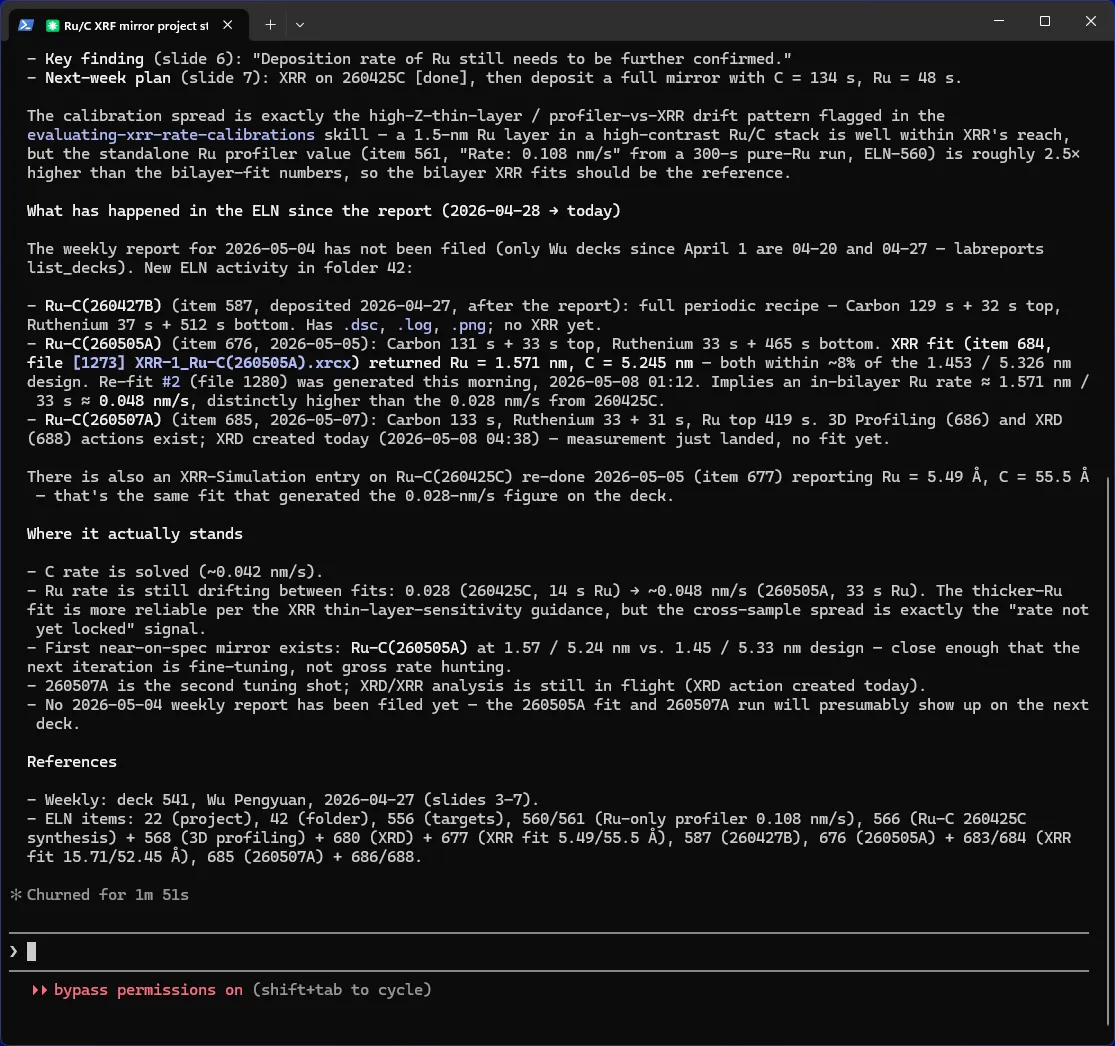
“What is the current state of the Ru/C XRF mirror project?” The model walks the most recent weekly-report deck, identifies the Ru deposition-rate calibration question raised at the meeting, then steps through every Ru/C entry in the notebook since that report — three new specimens, an XRR fit returned this morning, an XRD measurement that landed today — and returns a situation report with the rate spread named (≈0.028 to ≈0.048 nm/s) and the next decision flagged.
The shared structure is consistent. A natural-language question. MCP tool calls walking structured records. An answer with citations back to specific specimens, decks, and instruments. The PI does not learn a query language. The AI walks the records the way a senior student would, only in seconds.
The two substrates
The AI works because the records are there to be read. The lab notebook holds a hierarchy — project, folder, specimen, action, files — that resolves a question about a chamber or a researcher to specific samples and measurements rather than to chat history. The discipline of registering every experiment, attaching every measurement, and entering every parameter is the precondition for queries that return citations rather than guesses. A separate case study on this site describes the six years of unglamorous infrastructure work that produced that substrate, and what changed the month an AI could finally read it. See Six Years to AI: how one lab built the infrastructure that made AI useful.
The same AI reaches back into projects that ended years ago. A research group’s institutional memory becomes queryable when finished projects are ingested with the same discipline as live ones. A six-year-old archive of work on quasicrystalline thin films, spanning two journal papers and three students across four time zones, was poured into the notebook in March 2026 — at a cost of roughly ten hours per paper, and produced cross-paper specimen lineage that had previously lived only in the original authors’ memories. See Legacy data has a second life.
For the PI considering this approach
Three observations from the group described above, offered to PIs considering similar tooling.
First, the structured lab notebook is a multi-year commitment, not a quarter-long project. The substrate must be in place before AI roadmap discussions are productive — language models cannot recover what was never recorded.
Second, operational tooling — weekly-report indexing, recipe registries, performance-review pipelines — should accumulate incrementally, as a query repeats often enough to deserve automation. Premature systematization produces folders of unused scripts.
Third, treat the operational layer as code in version control rather than as documents in a shared drive. Language models work against repositories better than they work against folders of mixed-format files. The interesting work — the analysis the AI does on top — assumes that the layer beneath it is already there.